LLM Decoder Architecture Explained
Modern LLMs use decoder-only Transformer architecture... but what exactly does that mean?
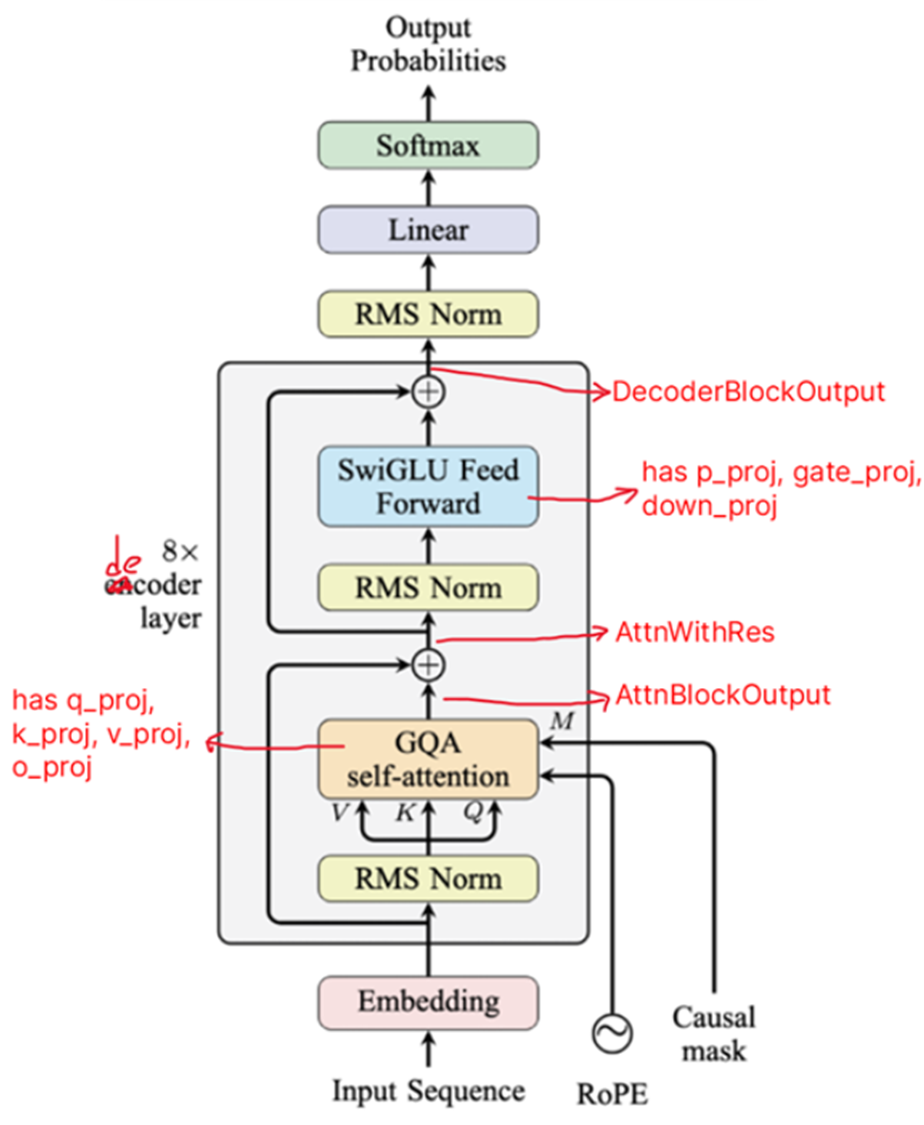
Decoder-only architecture
A decoder-only LLM consists of N decoder blocks, followed by a final Norm + Linear + Softmax
- Embedding Layer
- Decoder Block 1
- Decoder Block 2
...
- Decoder Block N
- Layer Norm
- Linear Layer
- Softmax
Each Decoder Block consists of one Multi-Head Self-Attention block and one MLP (Feed-Forward) module
- Layer Norm
- Multi-Head Self-Attention (contains q_proj, k_proj, v_proj, o_proj)
- Layer Norm
- Feed Forward Network (consists of 3 separate linear layers, having weights gate_proj, up_proj, down_proj)
The Self-Attention block has
- Multiple attention heads, each having their own Q, K, V projections (
q_proj,k_proj,v_proj) - One output projection (
o_proj). The output from all heads are concatenated & ran through o_proj, effectively mixing all heads back together
After this self-attention block, the Layer Norm & feed-forward layer is applied.
Even though we say each attn head has its own Q, K, V projection matrices, the model actually stores ONE big matrix per block
q_proj: [batch_size, seq_len, hidden_size]
k_proj: [batch_size, seq_len, hidden_size]
v_proj: [batch_size, seq_len, hidden_size]
Take the q_proj (W_q) as an example. d_model is the hidden_dim, and H is the number of attn heads
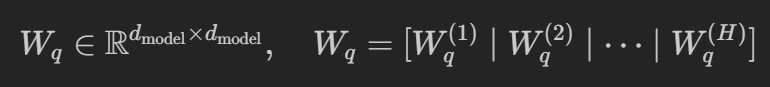
Note that implementation wise, we never explicitly split the W_q proj matrix into num_heads smaller matrices
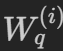
We only split the output matrix Q, which is obtained after applying the projection (Q = x @ W_q). This applies to all Q, K, V
Example
Assume our hidden_size is 4096, and we have 32 heads. So, the head_dim will be 4096/32 = 128. That means our projection matrix is comprised of 32 heads, each containing 128 weights. After projection, our Q, K, V matrices will be split into 32 matrices, with each matrix going to one head
Taking Q as an example
- After projection, we get a
(batch_size, seq_len, 4096)matrix - We split the matrix into 32 separate heads, reshaping it into a
(batch_size, seq_len, 32, 128)matrix
Summary of Model ops
To summarize the decoder-only architecture's operations
- Input tokens are passed through the token embedding layer
- They're then passed through N decoder blocks. In each decoder block:
- Passed through LayerNorm
- Passed through Self-Attention Block
- Get Q, K, V matrices by multiplying input with W_q, W_k, W_v projection matrices
- Split Q, K, V matrices into num_head independent outputs
- Apply RoPE to Q, K
- Run operations on each independent output
- Concatenate (merge) all independent outputs
- Apply the W_o output projection matrix on this concatenated matrix
- Residual add (with decoder block input)
- Passed through LayerNorm
- Passed through Feed Forward Network
- Apply up projection matrix W_up
- Apply gate projection matrix W_gate
- Apply activation on gate projection output
- Hadamard product (element-wise multiplication) on the outputs of step 1, step 3
- Apply down projection matrix W_down
- Residual add (with self-attention block output)
- Output is passed as input to the next decoder block
- Output of the final decoder block is passed through a Norm -> Linear -> Softmax
Decoder-Only Transformer Operations
1. Token Embedding Layer
We start with a matrix having shape (batch_size, seq_len). We pass it through our embedding matrix to get a matrix of shape (batch_size, seq_len, hidden_dim)
Since we're using Rotary positional encodings (RoPE), we don't add any positional encodings to the token embeddings at the input. Instead, positional information is injected later, inside the self-attention mechanism - directly into the Q and K matrices.
The output of the embedding goes into the decoder blocks
START: Decoder Block Operations
2. Layer Norm
x_norm = Norm(x), where x_norm has shape (batch_size, seq_len, hidden_dim)
START: Self-attention Block
3. Linear projection to calculate the Q, K, V matrices
Q = x_norm @ W_q = (batch_size, seq_len, hidden_dim)
K = x_norm @ W_k = (batch_size, seq_len, hidden_dim)
V = x_norm @ W_v = (batch_size, seq_len, hidden_dim)
4. Q, K, V matrices are split (reshaped) into num_head independent outputs
The last dimension (hidden_dim) is split into (num_heads, head_dim)
Q => (batch_size, seq_len, num_heads, head_dim)
K => (batch_size, seq_len, num_heads, head_dim)
V => (batch_size, seq_len, num_heads, head_dim)
5. Apply RoPE on Q, K matrices
RoPE is applied on the last dimension head_dim. RoPE rotates every 2D pair inside the token's Q and K matrix using the token's position t, where the 1st token in the sequence has t=0, the 2nd token has t=1, etc...
Q has shape (batch_size, seq_len, num_heads, head_dim). RoPE is applied independently for every batch element b, token position t, and attention head h
Assume the Q matrix for the first token position (t=0) across the batch has shape (8, 1, 2, 4). Here, batch_size=8, num_heads=2, and each head has head_dim=4 values
One Q head vector looks like [q1, q2, q3, q4]. Since head_dim=4, we get 2 RoPE pairs per head: (q1, q2), (q3, q4)
All pairs for this token use the same token position t=0 for rotation. This rotation is applied across all heads, across all token positions in the sequence, and across all sequences in the batch.

We repeat this whole process for the K vector
Q = RoPE(Q)
K = RoPE(K)
The output shape is unchanged: (batch_size, seq_len, num_heads, head_dim)
6. Apply operations for each independent output

This gives us the result of ONE independent output. This result has shape (batch_size, seq_len, head_dim)
7. Concatenate all independent outputs
We have a total of num_heads independent outputs. We concatenate (merge) them into a single matrix, giving us a matrix of shape (batch_size, seq_len, num_heads, head_dim). Then, we flatten the last 2 dimensions, giving us a matrix of shape (batch_size, seq_len, hidden_dim) Remember that hidden_dim = num_heads x head_dim.
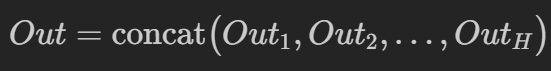
We now have the Output matrix having shape (batch_size, seq_len, hidden_dim)
8. Apply the Output Projection
We multiply this Output matrix with the W_o output projection matrix, giving us the final matrix of shape (batch_size, seq_len, hidden_dim)

This is the output of our self-attention block, having shape (batch_size, seq_len, hidden_dim)
END: Self-attention Block
9. Add residual x
We add the original input x to the self-attention block's output $$ AttnWithRes = x + AttnBlockOutput $$
10. Pass Self-Attention block output to Decoder Block's Layer Norm + Feed Forward Layer
The output of the self-attention block is passed through the Layer Norm. Then, it is passed to the Feed Forward Network, which has 3 linear layers having the weights gate_proj, up_proj, down_proj.
This is the shape of our weight matrices for the FFN, where ff_dim is the dimension of our FFN
up_proj (W_up) = (hidden_dim, ff_dim)
gate_proj (W_gate) = (hidden_dim, ff_dim)
down_proj (W_down) = (ff_dim, hidden_dim)

- Apply Layer Norm
X_norm = Norm(AttnWithRes), where X_norm has shape(batch_size, seq_len, hidden_dim) - Up Projection U = X_norm @ W_up, where U has shape
(batch_size, seq_len, ff_dim) - Gate Projection G = X_norm @ W_gate, where G has shape
(batch_size, seq_len, ff_dim) - Elementwise Gating H = U ⊙ SiLU(G), where H has shape
(batch_size, seq_len, ff_dim). ⊙ is the Hadamard product, which is just element-by-element multiplication of two matrices of the same shape. SiLU is the activation function applied on the output of the gate projection. - Down Projection M = H @ W_down, where M has shape
(batch_size, seq_len, hidden_dim) - Add residual
AttnWithResDecoderBlockOutput = AttnWithRes + M, where DecoderBlockOutput has shape(batch_size, seq_len, hidden_dim)
So, the output of the decoder block has shape (batch_size, seq_len, hidden_dim)
END: Decoder Block Operations
11. Pass Decoder Block output to next module
The output of the decoder block is passed as input to the next decoder block. If we're at the last decoder block, then the output is passed to the Layer Norm + Linear Layer of the Transformer model.
Important!
Note that many of the original mechanisms are now outdated!
- MHA (Multi-head attention) has many variants like MQA (Multi-query attention), GQA (Grouped-query attention), MLA (Multi-latent attention), all which reduce the number of distinct KV representations, and hence reduce the KV cache memory usage

- Positional Encodings now include RoPE (Rotary Position Embeddings), No Position Embeddings (NoPE), RNoPE Hybrid approaches.... all which serve to better encode position and work with longer contexts
- Using gated activation functions like SwiGLU, GEGLU over ReLU
- Using FlashAttention-style implementations to minimize GPU memory access
- Updated variants like MoE
- Hybrid models like State Space Models, Linear Attention...